Project 1¶
Step 1: Load the data and perform basic operations.¶
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from statistics import mode
from scipy.stats import stats
1. Load the data in using pandas.¶
act = pd.read_csv("../data/act.csv")
sat = pd.read_csv("../data/sat.csv")
2. Print the first ten rows of each dataframe.¶
act.head(10)
sat.head(10)
3. Describe in words what each variable (column) is.¶
We are given data about state-wide ACT and SAT scores, including the statewide participation rate.
The columns for each are as follows:
- "Unnamed:0" - unique identifier
- "State" - State name
- "Participation" - what percentage of high school seniors took the exam
ACT columns:
- "English" - the statewide average score on the English section of the ACT
- "Math" - the statewide average score on the Math section of the ACT
- "Reading" - the statewide average score on the Reading section of the ACT
- "Science" the statewide average score on the Science section of the ACT
- "Composite" - each exam taker's nomial ACT score is refered to as their composite. Composites are the average of the three sections on the ACT. This column represents the statewide average score on the ACT.
SAT columns:
- "Evidence-Based Reading and Writing" - the statewide average score on the Reading/Writing section of the SAT
- "Math" - the statewide average score on the Math section of the SAT
- "Total" - each exam taker's nomial SAT score is the sum of the scores on the two sections. This column represents the statewide average score on the SAT.
Limitations:
- Notice that the SAT data does not contain a row with the national averages, therefore Unique Identifiers will not align in the datasets. We will need to merge by State if we choose to do so.
4. Does the data look complete? Are there any obvious issues with the observations?¶
Checks completed for ACT and SAT datasets
- Duplicates
- Unreasonable values
- Any mean values that exceed the maximum possible value
- Range of subject scores are not extreme for any one state
- Any extreme differences between the calculated Composite or Total and the one given in the data
ACT data¶
sum(act.duplicated())
# Here we will see the max and min of each column
# We want to make sure no maximum exceeds 36, the maximum score on the ACT
act[["English", "Math", "Reading", "Science"]].describe()
# Here we will strip the percentage sign from the "Participation" column
# So we can later sort and determine that its max and min are reasonable.
act["Participation"] = act.apply(lambda x: int(x["Participation"].replace("%","")), axis =1)
act["Participation"].describe()
act.sort_values("Participation").head(5)
# As the source blog indicates, Maine has the lowest participation rate in the ACT.
# This indicates that the SAT is the dominant exam in that part of the country.
# Create column that calculates range of subject scores
def a_range(alist):
a = max(alist)
b = min(alist)
return a-b
act['score_range'] = act.apply(lambda x: a_range([x["English"],x["Math"],x["Reading"],x["Science"]]), axis=1)
act["score_range"].value_counts()
# There are no outrageous differences between the maximum and minimum scores per state, they are reasonable.
# We can assume there aren't any erroneous outlier values.
# Create column to make sure Composites are reasonable.
act['checkcol'] = act.apply(lambda x: np.mean([x["English"],x["Math"], x["Reading"], x["Science"]]), axis=1)
act["diff_check"] = act.apply(lambda x: x["Composite"]-x["checkcol"], axis =1)
act["diff_check"].value_counts()
# Here we see that there's slight differences between the Composite and true average of the scores.
# Perhaps there is a weighting in its calculation we do not know about. It is not provided from the source site.
SAT data¶
sat.head()
sum(sat.duplicated())
# Here we will see the max and min of each column
# We want to make sure no score maximum exceeds 800, the maximum score on a single section of the SAT
# Also, we're going to see that no Total exceeds 1600
sat[["Evidence-Based Reading and Writing", "Math", "Total"]].describe()
# Nothing looks out of line, everything looks reasonable.
# I think the "Evidence-Based Reading and Writing" column name is too long to type over and over.
# We're going to change its name to "ReadingWriting".
sat = sat.rename(columns={'Evidence-Based Reading and Writing': 'ReadingWriting'})
# Here we will strip the percentage sign from the "Participation" column
# So we can later sort and determine that its max and min are reasonable.
sat["Participation"] = sat.apply(lambda x: int(x["Participation"].replace("%","")), axis =1)
sat["Participation"].describe()
sat.sort_values("Participation").head(5)
# Wow, there are some very low SAT participation percentages.
# Perhaps this means the dominant exam in those states is the ACT.
sat['score_range'] = sat.apply(lambda x: a_range([x["ReadingWriting"],x["Math"]]), axis=1)
sat["score_range"].value_counts()
# These are reasonable ranges between state-wide average SAT section scores.
# We can assume there are no erroneous outlier values.
# Create column to make sure Composites are reasonable.
sat['checkcol'] = sat.apply(lambda x: np.sum([x["ReadingWriting"],x["Math"]]), axis=1)
sat["diff_check"] = sat.apply(lambda x: x["Total"]-x["checkcol"], axis =1)
act["diff_check"].value_counts()
# Here we see that there's slight differences between the Total and true sum of the scores.
# Perhaps there is a weighting in its calculation we do not know about. It is not provided from the source site.
5. Print the types of each column.¶
act.info()
sat.info()
6. Do any types need to be reassigned? If so, go ahead and do it.¶
# Previously in my data reasonability tests I removed the percentage sign and changed "Participation"
# to integer (from object) in both tables. I already had the foresight to do this.
7. Create a dictionary for each column mapping the State to its respective value for that column. (For example, you should have three SAT dictionaries.)¶
ACT dictionaries¶
act_part = {}
for i in range(len(act)):
act_part[act["State"][i]] = act["Participation"][i]
act_eng = {}
for i in range(len(act)):
act_eng[act["State"][i]] = act["English"][i]
act_math ={}
for i in range(len(act)):
act_math[act["State"][i]] = act["Math"][i]
act_read = {}
for i in range(len(act)):
act_read[act["State"][i]] = act["Reading"][i]
act_sci = {}
for i in range(len(act)):
act_sci[act["State"][i]] = act["Science"][i]
SAT dictionaries¶
sat_part ={}
for i in range(len(sat)):
sat_part[sat["State"][i]] = sat["Participation"][i]
sat_rdwt ={}
for i in range(len(sat)):
sat_rdwt[sat["State"][i]] = sat["ReadingWriting"][i]
sat_math={}
for i in range(len(sat)):
sat_math[sat["State"][i]] = sat["Math"][i]
8. Create one dictionary where each key is the column name, and each value is an iterable (a list or a Pandas Series) of all the values in that column.¶
ACT dictionaries long¶
act_dict_long = {}
cols =["State", "Participation", "English", "Math", "Reading", "Science"]
for j in cols:
a_list=[]
for i in range(len(act)):
a_list.append(act[j][i])
act_dict_long[j] = a_list
act_dict_long
SAT dictionaries long¶
sat_dict_long = {}
cols =["State", "Participation", "ReadingWriting", "Math"]
for j in cols:
a_list=[]
for i in range(len(sat)):
a_list.append(sat[j][i])
sat_dict_long[j] = a_list
sat_dict_long
9. Merge the dataframes on the state column.¶
#Before we merge data frames, I'm going to do some serious column renames.
act = act.rename(columns={"State":"state",'Participation': 'partic-act', 'English':"eng-act", "Math":"math-act",
"Reading":"read-act", "Science":"sci-act", "Composite":"comp-act",
"score_range":"score-range-act","checkcol":"checkcol-act", "diff_check":"diff-check-act"})
sat = sat.rename(columns={"State":"state","Participation":"partic-sat", "ReadingWriting":"readwrite-sat",
"Math":"math-sat", "Total":"total-sat", "score_range":"score-range-sat", "checkcol":"checkcol-sat", "diff_chec":"diff-check-sat"})
sat_act = pd.merge(act, sat, on = "state", how = "outer")
sat_act.head()
10. Change the names of the columns so you can distinguish between the SAT columns and the ACT columns.¶
# I already had the foresight to do this.
11. Print the minimum and maximum of each numeric column in the data frame.¶
# I am choosing to show this in two ways in case one is visibly easier to read despite providing
# more information than what was asked.
num_sat_act = sat_act[["state","partic-act", 'eng-act', 'math-act', 'read-act','sci-act','comp-act','score-range-act', 'partic-sat',
'readwrite-sat','math-sat','total-sat', 'score-range-sat']]
num_sat_act.head()
#remove national average for act, to remove null values
num_sat_act = num_sat_act[1:]
len(num_sat_act.columns[0])
num_sat_act.head()
num_sat_act.columns
len(num_sat_act["partic-act"])
num_sat_act["partic-act"][1]
min_max ={}
for col in num_sat_act.columns[1:]:
a_list=[]
for i in range(1, len(num_sat_act[col])): #we need to start at 1 - we've removed index 0, the national average for act scores
a_list.append(num_sat_act[col][i])
min_max[col] = "Max: "+str(max(a_list))+", Min: "+str(min(a_list))
min_max
desc_dict = {}
desc_dict["field"] = list(num_sat_act.columns[1:])
min_list =[]
max_list=[]
for col in num_sat_act.columns[1:]:
b_list = []
for i in range(1,len(num_sat_act)):
b_list.append(num_sat_act[col][i])
minimum = min(b_list)
maximum = max(b_list)
min_list.append(minimum)
max_list.append(maximum)
desc_dict["min"] = min_list
desc_dict["max"] = max_list
desc_dict
desc_df=pd.DataFrame(desc_dict)
desc_df
num_sat_act.describe()
12. Write a function using only list comprehensions, no loops, to compute standard deviation. Using this function, calculate the standard deviation of each numeric column in both data sets. Add these to a list called sd.¶
$$\sigma = \sqrt{\frac{1}{n}\sum_{i=1}^n(x_i - \mu)^2}$$
def fsd(col, table): #used "fsd" for function of standard deviation
xmu = [(x-np.mean(table[col]))**2 for x in table[col]]
return ((sum(xmu)/len(xmu))**.5)
sd = [fsd(x, num_sat_act) for x in num_sat_act.columns[1:]]
sd
Step 2: Manipulate the dataframe¶
13. Turn the list sd into a new observation in your dataset.¶
# I already had the foresight to display this with .describe().
# The standard deviation values I calculated are slightly different than
# the ones calculated in .describe(). .describe() must use the formula
# for the standard deviation of a sample (versus entire population).
# I will do so again, guessing at the assignment's requested methodology.
# We will append this observation to our Descriptive Statistics DataFrame, desc_df
desc_dict["sd"] = sd
desc_df=pd.DataFrame(desc_dict)
desc_df
14. Sort the dataframe by the values in a numeric column (e.g. observations descending by SAT participation rate)¶
# The prompt appears to switch back to the dataframe containing numerical values for each state.
num_sat_act.sort_values("partic-act", ascending = False)
15. Use a boolean filter to display only observations with a score above a certain threshold (e.g. only states with a participation rate above 50%)¶
num_sat_act[num_sat_act["partic-sat"]>50]
#number of states that require the SAT
len(num_sat_act[num_sat_act["partic-sat"]==100])
#number of states that require the ACT
len(num_sat_act[num_sat_act["partic-act"]==100])
Step 3: Visualize the data¶
Here we interpret distribution as the value counts for each participation percentage. Reiterated for clarity.
sat_partic = pd.DataFrame(num_sat_act["partic-sat"].value_counts())
sat_partic.reset_index(inplace = True)
plt.hist(sat_partic["index"], bins = 15)
plt.title("SAT Participation Distribution")
plt.show()

On the SAT there are a number of states with 100% participation, indicating it is part of that state's high school graduation requirements.
In states where there is a particular low participation rate, it is possible that the dominant exam in that state is the ACT.
act_partic = pd.DataFrame(num_sat_act["partic-act"].value_counts())
act_partic.reset_index(inplace = True)
plt.hist(act_partic["index"], bins = 15)
plt.title("ACT Participation Distribution")
plt.show()

On the ACT there are a number of states with 100% participation, indicating it is part of that state's high school graduation requirements.
In states where there is a particular low participation rate, it is possible that the dominant exam in that state is the SAT.
More states require the ACT for graduation than require the SAT.
17. Plot the Math(s) distributions from both data sets.¶
ACT Math Scores¶
act_math = pd.DataFrame(num_sat_act["math-act"].value_counts())
act_math.reset_index(inplace = True)
plt.hist(act_math["index"], bins = 15)
plt.title("ACT Math Score Distribution")
plt.show()

SAT Math Scores¶
sat_math = pd.DataFrame(num_sat_act["math-sat"].value_counts())
sat_math.reset_index(inplace = True)
plt.hist(sat_math["index"], bins = 15)
plt.title("SAT Math Score Distribution")
plt.show()

plt.figure(1)
plt.subplot(211)
plt.hist(act_math["index"], bins = 15)
plt.title("ACT Math Score Distribution")
plt.subplot(212)
plt.hist(sat_math["index"], bins = 15)
plt.title("SAT Math Score Distribution")
fig = plt.gcf()
fig.subplots_adjust(hspace = 0.5)
plt.show()

18. Plot the Verbal distributions from both data sets.¶
ACT Verbal¶
act_read = pd.DataFrame(num_sat_act["read-act"].value_counts())
act_read.reset_index(inplace = True)
act_eng = pd.DataFrame(num_sat_act["eng-act"].value_counts())
act_eng.reset_index(inplace=True)
x = act_read["index"]
y = act_eng["index"]
bins = 15
plt.hist(x, bins, alpha=0.5, label='ACT Reading Score')
plt.hist(y, bins, alpha=0.5, label='ACT English Score')
plt.legend(loc='upper right')
plt.title("ACT Verbal Score")
plt.show()

I plotted ACT Reading and ACT English over one another because I wanted to considering how similar they were to one another and dually how similar they were to the distribution of the SAT Verbal section.
SAT Verbal¶
sat_verb = pd.DataFrame(num_sat_act['readwrite-sat'].value_counts())
sat_verb.reset_index(inplace=True)
plt.hist(sat_verb["index"], bins = 15)
plt.title("SAT Verbal Score Distribution")
plt.show()

x = act_read["index"]
y = act_eng["index"]
bins = 15
plt.hist(x, bins, alpha=0.5, label='ACT Reading Score')
plt.hist(y, bins, alpha=0.5, label='ACT English Score')
plt.legend(loc='upper right')
plt.title("ACT Verbal Score")
plt.show()
ACT English scores show a histogram more similar to the SAT Verbal scores
19. When we make assumptions about how data are distributed, what is the most common assumption?¶
Many times we assume that the distribution is normally distributed. We can do so because of the Central Limit Theorem.
20. Does this assumption hold true for any of our columns? Which?¶
Judging by the histograms, none of our columns are normally distributed.
21. Plot some scatterplots examining relationships between all variables.¶
num_sat_act.columns
plt.rcParams['figure.figsize'] =(20,20)
pd.plotting.scatter_matrix(num_sat_act[["partic-act", "comp-act", "partic-sat","total-sat"]], alpha = 1, diagonal ='kde')
plt.show()

That was a great way to see a bunch of scatters at once, but for clarity, we will look at a few of them individually.
len((list(enumerate(num_sat_act["state"]))))
fig, ax = plt.subplots()
y = num_sat_act["partic-act"]
z = num_sat_act['partic-sat']
ax.scatter(y, z)
plt.ylabel('Participation in SAT')
plt.xlabel('Participation in ACT')
plt.title("ACT participation x SAT participation")
plt.show()

Here we see that exam participation rates have an inverse relationship. For example, the higher the participation in the SAT, the lower the participation in the ACT. These variables are negatively correlated. We can conclude that this confirms an either/or relationship many High School seniors have towards the ACT and SAT.
Except in Florida. With a wopping 73% participation on the ACT and 83% on the SAT.
plt.figure()
plt.subplot(221) #2 rows, cols, plot
plt.scatter(num_sat_act["partic-act"], num_sat_act["total-sat"])
plt.ylabel('SAT Score')
plt.xlabel('Participation in ACT')
plt.title("ACT participation x SAT Score")
plt.subplot(222) #2 rows, col, plot
plt.scatter(num_sat_act["partic-sat"], num_sat_act["comp-act"])
plt.ylabel('ACT Score')
plt.xlabel('Participation in SAT')
plt.title("SAT participation x ACT Score")
plt.subplot(224) #2 rows, col, plot
plt.scatter(num_sat_act["partic-sat"], num_sat_act["total-sat"])
plt.ylabel('SAT Score')
plt.xlabel('Participation in SAT')
plt.title("SAT participation x SAT Score")
plt.subplot(223) #2 rows, col, plot
plt.scatter(num_sat_act["partic-act"], num_sat_act["comp-act"])
plt.ylabel('ACT Score')
plt.xlabel('Participation in ACT')
plt.title("ACT participation x ACT Score")
fig = plt.gcf()
fig.subplots_adjust(hspace = 0.5)
plt.show()

We know the higher the participation rate for a particular exam indicates a lower total average score.
Here we see that in general, ACT participation rate and SAT Score are directly related. This could be because where the ACT is required to graduate from high school, only the best exam takers will opt to take the SAT. This confirms an either/or approach taken by exam takers.
plt.scatter(num_sat_act["comp-act"], num_sat_act["total-sat"])
plt.ylabel('SAT Score')
plt.xlabel('ACT Score')
plt.title("ACT Score x SAT Score")
plt.show()

np.corrcoef(num_sat_act["total-sat"],num_sat_act["comp-act"])
Here we see that there is a loose, inverse relationship between SAT and ACT scores. This relationship is not as strong because states that require a specific exam as a highschool diploma pre-requisite are being compared to states where only college bound seniors elect to take it. The correlation between ACT and SAT scores weakens when comparing whole population scores versus self selecting samples.
plt.scatter(num_sat_act["score-range-sat"], num_sat_act["score-range-act"])
plt.ylabel('ACT score range')
plt.xlabel('SAT score range')
plt.title("ACT and SAT section score ranges")
plt.show()

This was just for fun. I wanted to observe the relationship between ACT section score range and SAT section score range. Is it more likely that exam takers will have a higher range between sections on the SAT or ACT even though they are ostensibly over similar topics? Our graph indicates not really.
plt.scatter(num_sat_act["math-act"], num_sat_act["math-sat"])
plt.ylabel('SAT Math')
plt.xlabel('ACT Math')
plt.title("ACT Math x SAT Math")
plt.show()

np.corrcoef(num_sat_act["math-sat"],num_sat_act["math-act"])
#No correlation.
22. Are there any interesting relationships to note?¶
A lot of the relationships can be summarized by the inverse relationship between participation rate and composite score. For example, the higher the participation rate for an exam, the lower the scores for that particular exam.
Exam participation rates also have an inverse relationship. For example, the higher the participation rate for one exame indicates a lower participation rate on the other.
I found it interesting that the ACT composite and SAT total scores are not directly correlated. I suspect this arises from states requiring one or the other for high school graduation while the other is optional. The exam that is required will have lower overall scores and the one that is elective will have higher scores.
23. Create box plots for each variable.¶
x = num_sat_act[["partic-act", "comp-act", "partic-sat","total-sat"]]
x.plot.box()
plt.show()

We see that ACT composites do not vary as much as the other columns evaluated do. This is because the ACT score has a maximum of 25.5 and minimum of 17.8. This is a range of 7.7 which is miniscule when scaled next to the ranges of other variables.
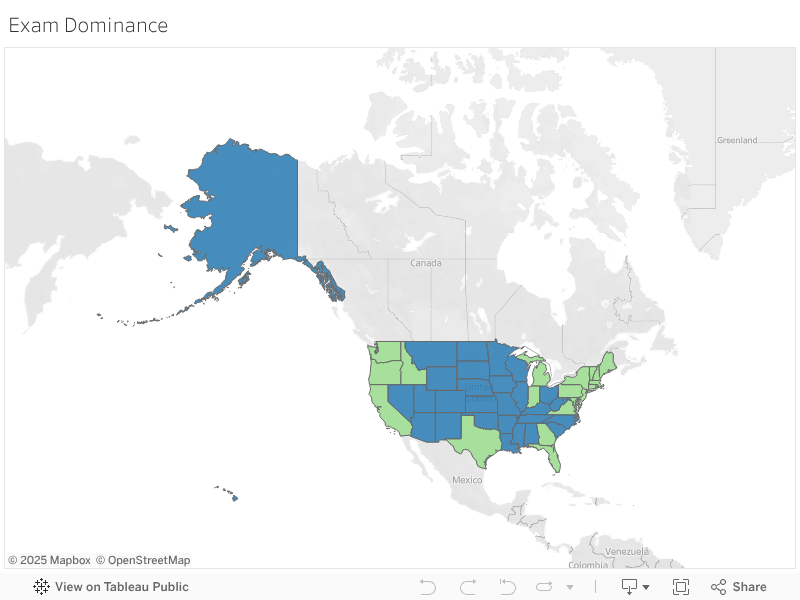
BONUS: Using Tableau, create a heat map for each variable using a map of the US.¶
heat_map = num_sat_act.loc[:,["state","partic-sat","partic-act"]]
heat_map["dom-exam"] = heat_map.apply(lambda x: x["partic-sat"]>x['partic-act'], axis =1)
heat_map.to_csv("../data/sat_act_data.csv",index = False)
%%HTML
<div class='tableauPlaceholder' id='viz1507263529905' style='position: relative'><noscript><a href='#'><img alt='Exam Dominance ' src='https://public.tableau.com/static/images/SA/SATACTdominance/ExamDominance/1_rss.png' style='border: none' /></a></noscript><object class='tableauViz' style='display:none;'><param name='host_url' value='https%3A%2F%2Fpublic.tableau.com%2F' /> <param name='embed_code_version' value='2' /> <param name='site_root' value='' /><param name='name' value='SATACTdominance/ExamDominance' /><param name='tabs' value='no' /><param name='toolbar' value='yes' /><param name='static_image' value='https://public.tableau.com/static/images/SA/SATACTdominance/ExamDominance/1.png' /> <param name='animate_transition' value='yes' /><param name='display_static_image' value='yes' /><param name='display_spinner' value='yes' /><param name='display_overlay' value='yes' /><param name='display_count' value='yes' /><param name='filter' value='publish=yes' /></object></div> <script type='text/javascript'> var divElement = document.getElementById('viz1507263529905'); var vizElement = divElement.getElementsByTagName('object')[0]; vizElement.style.width='100%';vizElement.style.height=(divElement.offsetWidth*0.75)+'px'; var scriptElement = document.createElement('script'); scriptElement.src = 'https://public.tableau.com/javascripts/api/viz_v1.js'; vizElement.parentNode.insertBefore(scriptElement, vizElement); </script>
Heatmap of the 30 open states:
heat_map2 = num_sat_act.loc[:,["state","partic-sat","partic-act"]]
heat_map2["open"] = heat_map.apply(lambda x: ((x["partic-sat"]!=100)&(x['partic-act']!=100)), axis =1)
heat_map2.to_csv("../data/sat_act_open_states.csv",index = False)
%%HTML
<div class='tableauPlaceholder' id='viz1507272906441' style='position: relative'><noscript><a href='#'><img alt='Open States ' src='https://public.tableau.com/static/images/PN/PNFSRPBXX/1_rss.png' style='border: none' /></a></noscript><object class='tableauViz' style='display:none;'><param name='host_url' value='https%3A%2F%2Fpublic.tableau.com%2F' /> <param name='embed_code_version' value='2' /> <param name='path' value='shared/PNFSRPBXX' /> <param name='toolbar' value='yes' /><param name='static_image' value='https://public.tableau.com/static/images/PN/PNFSRPBXX/1.png' /> <param name='animate_transition' value='yes' /><param name='display_static_image' value='yes' /><param name='display_spinner' value='yes' /><param name='display_overlay' value='yes' /><param name='display_count' value='yes' /><param name='filter' value='publish=yes' /></object></div> <script type='text/javascript'> var divElement = document.getElementById('viz1507272906441'); var vizElement = divElement.getElementsByTagName('object')[0]; vizElement.style.width='100%';vizElement.style.height=(divElement.offsetWidth*0.75)+'px'; var scriptElement = document.createElement('script'); scriptElement.src = 'https://public.tableau.com/javascripts/api/viz_v1.js'; vizElement.parentNode.insertBefore(scriptElement, vizElement); </script>

Step 4: Descriptive and Inferential Statistics¶
24. Summarize each distribution. As data scientists, be sure to back up these summaries with statistics. (Hint: What are the three things we care about when describing distributions?)¶
Data scientists care about the following things
- center: mean, median, mode
- spread: standard deviation, variance, range
- shape: skew, symmetric
I will proceed to describe the distributions of SAT score, SAT participation, ACT score and ACT participation using the aforementioned descriptors.
SAT Score and Participation¶
As a refresher here is what distributions look like:
act_total = pd.DataFrame(num_sat_act["comp-act"].value_counts())
act_total.reset_index(inplace = True)
sat_total = pd.DataFrame(num_sat_act["total-sat"].value_counts())
sat_total.reset_index(inplace = True)
plt.subplot(221)
plt.hist(act_partic["index"], bins = 10)
plt.title("ACT Participation Distribution")
plt.subplot(222)
plt.hist(sat_partic["index"], bins = 10)
plt.title("SAT Participation Distribution")
plt.subplot(223)
plt.hist(act_total["index"], bins = 10)
plt.title("ACT Composite Scores")
plt.subplot(224)
plt.hist(sat_total["index"], bins = 10)
plt.title("SAT Total Scores")
plt.show()

from scipy import stats
def describe_dists(variable = ["comp-act", "total-sat", "partic-act", "partic-sat"]):
x = str(variable)
a_dict = {"comp-act":"ACT Score",
"total-sat": "SAT Score",
"partic-act": "ACT Participation",
"partic-sat":"SAT Participation"}
print ("Characteristics about "+a_dict[x]+" CENTER:")
print ("Mean: "+str(np.mean(num_sat_act[variable])))
print ("Median: "+str(np.median(num_sat_act[variable])))
try:
print ("Mode: "+str(mode(num_sat_act[variable])))
except:
pass
print(" ")
print ("Characteristics about "+a_dict[x]+" SPREAD:")
print ("Standard Deviation: "+str(np.std(num_sat_act[variable])))
print ("Variance: "+str(np.var(num_sat_act[variable])))
print ("Range: "+str(np.ptp(num_sat_act[variable])))
print(" ")
print ("Characteristics about "+a_dict[x]+" SHAPE:")
print ("Skewness: "+str(stats.skew(num_sat_act[variable])))
describe_dists("comp-act")
describe_dists("total-sat")
describe_dists("partic-act")
describe_dists("partic-sat")
25. Summarize each relationship. Be sure to back up these summaries with statistics.¶
This is done above after each of the scatter plots.
26. Execute a hypothesis test comparing the SAT and ACT participation rates. Use $\alpha = 0.05$. Be sure to interpret your results.¶
$H_0$ = there is no difference in the participation in exam A and the participation in exam B
$H_A$ = there is a difference in participation in exam A and exam B
# First we must find a p value.
stats.ttest_ind(num_sat_act["partic-act"], num_sat_act['partic-sat'], equal_var = False)
Based on the $p$ value, .0002, we can reject the null hypothesis. Since our t-statistic is positive, it suggests that participation in the ACT is higher than in the SAT.
I will also execute a hypothesis test comparing SAT and ACT participation rates in the 30 states that do not require either for high school graduation.¶
$H_0^2$ = there is no difference in the participation in exam A and the participation in exam B
$H_A^2$ = there is a difference in participation in exam A and exam B
num_sat_act2 = num_sat_act[(num_sat_act["partic-act"] != 100) & (num_sat_act["partic-sat"] != 100)]
stats.ttest_ind(num_sat_act2["partic-act"], num_sat_act2["partic-sat"], equal_var=False)
Based on the $p$ value, .7211244399, we fail to reject the null hypothesis. SAT still has the chance to win marketshare in the 30 open states!
27. Generate and interpret 95% confidence intervals for SAT and ACT participation rates.¶
conf_level = 0.95
mean = np.mean(num_sat_act["partic-sat"])
sigma = np.std(num_sat_act["partic-sat"])
n = len(num_sat_act["partic-sat"])
stats.norm.interval(conf_level, loc=mean, scale=sigma/(n ** 0.5)) ## n > 1
With 95% confidence, the average state participation rate in the SAT will be between 30.217 and 49.390.
conf_level = 0.95
mean = np.mean(num_sat_act["partic-act"])
sigma = np.std(num_sat_act["partic-act"])
n = len(num_sat_act["partic-act"])
stats.norm.interval(conf_level, loc=mean, scale=sigma/(n ** 0.5)) ## n > 1
With 95% confidence, the average state participation rate in the ACT will be between 56.5208 and 73.989.
28. Given your answer to 26, was your answer to 27 surprising? Why?¶
My answer to 27 was indicated by my answer to 26. I was not surprised.
29. Is it appropriate to generate correlation between SAT and ACT math scores? Why?¶
#recreated from above
plt.scatter(num_sat_act["math-act"], num_sat_act["math-sat"])
plt.ylabel('SAT Math')
plt.xlabel('ACT Math')
plt.title("ACT Math x SAT Math")
plt.show()
np.corrcoef(num_sat_act["math-sat"],num_sat_act["math-act"])
With correlation coefficient $-.5<|\rho| <.5$, it is not appropriate to generate correlation between math scores. This is in part because the effect participation rates have on average total score. Since we are comparing the ACT which is required in 17 states, and the SAT which is only required in 4 states, finding correlation between section scores is impossible.
30. Suppose we only seek to understand the relationship between SAT and ACT data in 2017. Does it make sense to conduct statistical inference given the data we have? Why?¶
If we only seek to understand the relationship between the SAT and ACT data for 2017, it makes sense to conduct statistical inference given the data we have because we can assume by the Central Limit Theorem that each sample in a whole population will reflect the whole and converge means and standard deviation statistics.
This isn't to say that additional context wouldn't be helpful in understanding the data from 2017. In addition to statistical inference, it would be beneficial to observe the trends of exam participation leading up to 2017 so we can fully understand how the 2017 SAT test changes affected participation in their first year.
heat_map.head()
satdom = heat_map[heat_map["dom-exam"]==True]
actdom = heat_map[heat_map["dom-exam"]==False]
satdom["diff"] = satdom.apply(lambda x: (x["partic-sat"]-x["partic-act"]), axis =1)
satdom.head()
actdom["diff"] = actdom.apply(lambda x: (x["partic-act"]-x["partic-sat"]), axis = 1)
actdom.head()
X1 = actdom["partic-act"]
Y1 = actdom["diff"]
X2 = satdom["partic-sat"]
Y2 = satdom["diff"]
plt.figure(figsize=(7,7))
plt.scatter(X1,Y1,color='red')
plt.scatter(X2,Y2,color='blue')
plt.legend(["ACT dominant", "SAT dominant"])
plt.title("How frequently do students take the non-dominant exam in their state?")
plt.xlabel("Participation Rate in dominant exam")
plt.ylabel("Difference between Participation Rate in dominant exam and non-dominant exam")
plt.show()

Above we see that in general, where the ACT is dominant, there are larger spreads between ACT and SAT participation rates.
Doing the t-test of means
$H_0$ = there is no difference in the difference between participation in the dominant and non-dominant exams. That is regardless of which exam is dominant, relative to the dominant exam, there are similar participation rates in the non-dominant exam.
$H_A$ = there is a difference in the difference between participation rates in the dominant and non-dominant exams. That is relative to the dominant exam, the non-dominant exam for one exam type, the non-dominant exam maintains a higher participation rate than the other.
For example, we might find where the SAT is dominant, students still take the ACT in high numbers, however where the ACT is dominant, very few people take the SAT.
# First we must find a p value.
stats.ttest_ind(actdom["diff"], satdom['diff'], equal_var = False)
Based on the $p$ value, .0000006989677, we can reject the null hypothesis. Since our t-statistic is positive, it suggests that even when the SAT is the dominant exam in the market, substantial numbers still take the ACT. The opposite does not hold true.